pandasの基礎知識¶
目次
データの参照と更新(loc / iloc)¶
DataFrameとSeriesのlocとilocは、データの参照や更新を行うための基本的な機能です。
次のように、行や列を指定することでデータを参照できます。なお、dfはDataFrame型の変数を、srはSeries型の変数を意味します。
df.loc[行の指定, 列の指定]
sr.loc[行の指定]
df.iloc[行の指定, 列の指定]
sr.iloc[行の指定]
また、次のように=で新しい値を代入すると、指定した行や列のデータを更新できます。
df.loc[行の指定, 列の指定] = 新しい値
sr.loc[行の指定] = 新しい値
df.iloc[行の指定, 列の指定] = 新しい値
sr.iloc[行の指定] = 新しい値
locでは、行名や列名を使って行や列を指定します。これに対し、ilocは行番号や列番号を使って指定します。行番号・列番号とは、0から始まる通し番号です。
locとilocでは、さまざまな記法が使えます。主に使うものを、下表にまとめました。なお、表内の※がついた記法には省略形があります。省略形も含め、各指定方法の詳細は次の項以降で説明します。
表:DataFrame.locとSeries.locの場合
| 指定方法 | 意味 | 記述例 |
|---|---|---|
| コロン | 全行(全列) | df.loc[:, :] |
| 行名(列名※) | 指定された行(列) | df.loc[10]df.loc[:, "Name"] |
| 行名のスライス※(列名のスライス) | スライスで指定された行(列) | df.loc[10:20]df.loc[:, "Name":"Point"] |
| 行名のリスト(列名のリスト※) | リストで指定された行(列) | df.loc[[10,20]]df.loc[:, ["Name"]] |
| 行の比較結果※(列の比較結果) | 比較結果がTrueの行(列) | df.loc[df["Point"] >= 80] |
表:DataFrame.ilocとSeries.ilocの場合
| 指定方法 | 意味 | 記述例 |
|---|---|---|
| コロン | 全行(全列) | df.iloc[:, :] |
| 行番号(列番号) | 指定された行(列) | df.iloc[0]df.iloc[:, 0] |
| 行番号のスライス※(列番号のスライス) | スライスで指定された行(列) | df.iloc[:2]df.iloc[:, :2] |
| 行番号のリスト(列番号のリスト) | リストで指定された行(列) | df.iloc[[0, 1]]df.iloc[:, [0]] |
行名・列名によるデータの参照・更新(loc)¶
DataFrame.locは、行名や列名でデータの取得や代入ができます。Series.locは、行名でデータの取得や代入ができます。
下記のdfとsrを使って、主な指定方法について順番に確認します。
df = pd.DataFrame(
[["Alice", 87], ["Bob", 65], ["Carol", 92]],
columns=["Name", "Point"],
index=[10, 20, 30],
)
df
Name |
Point |
|
|---|---|---|
10 |
Alice |
87 |
20 |
Bob |
65 |
30 |
Carol |
92 |
sr = df.Name # df["Name"]とも書けます
sr
10 Alice
20 Bob
30 Carol
Name: Name, dtype: object
コロンによる指定¶
行の指定や列の指定におけるコロン(:)は、全行や全列を意味します。もし列の指定を省略すると、:とみなされます。たとえば、df.loc[行の指定]はdf.loc[行の指定, :]と同じ結果になります。
行名(列名)による指定¶
df.loc[行名]は、指定した行(Series)になります。
df.loc[10]
Name Alice
Point 87
Name: 10, dtype: object
sr.loc[行名]は、指定した行の要素になります。
sr.loc[10]
'Alice'
列名を使った指定は、df.loc[:, 列名]のように記述します。結果はSeriesになります。
df.loc[:, "Name"]
10 Alice
20 Bob
30 Carol
Name: Name, dtype: object
列名による指定の省略形¶
列の指定では、省略形としてdf[列名]が使えます。
たとえば、下記の2行は同じ結果になります。
df.loc[:, "Name"]
df["Name"]
簡潔に記述できるため、実務では省略形を使うことをおすすめします。
ただし、下記のように省略形に行名を指定して更新しようとすると警告がでます。
df2 = df.copy()
df2["Name"][20] = "Bill"
これは、df2["Name"]がコピーを返す可能性があり、その場合更新が無視されるからです。
行名を指定して更新したい場合は、下記のようにlocを使いましょう。
df2.loc[20, "Name"] = "Bill"
行名のスライス(列名のスライス)による指定¶
df.loc[行名1:行名2]のように行名のスライスを使って指定すると、行名1から行名2までの行を抜き出したDataFrameやSeriesになります。リストのスライスに似ていますが、リストでは終了位置の要素を含まないのに対し、locでは終了位置の行を含みます。たとえば、下記は行名が20の行を含みます。
df.loc[10:20]
Name |
Point |
|
|---|---|---|
10 |
Alice |
87 |
20 |
Bob |
65 |
sr.loc[10:20]
10 Alice
20 Bob
Name: Name, dtype: object
列名のスライスも同様です。df.loc[行の指定, 列名1:列名2]のように、列名のスライスを使って指定すると、列名1から列名2までの列を抜き出したDataFrameになります。なお、行名のスライス同様、終了位置の列名2を含みます。
columns = ["Jan", "Feb", "Mar", "Apr"]
df4 = pd.DataFrame([[1, 2, 3, 4]], columns=columns)
df4.loc[:, "Feb":"Apr"]
Feb |
Mar |
Apr |
|
|---|---|---|---|
0 |
2 |
3 |
4 |
行名のスライスによる指定の省略形¶
行名が文字列型の場合、df.loc[行名のスライス]はlocを省略してdf[文字列のスライス]のように記述できます。
下記は、行名を文字列型にしたdf3のスライスの例です。
df3 = df.copy()
df3.index = df3.index.astype(str)
df3["10":"20"]
Name |
Point |
|
|---|---|---|
10 |
Alice |
87 |
20 |
Bob |
65 |
Seriesの場合も同様です。下記は、行名を文字列型にしたsr3のスライスの例です。
sr2 = sr.copy()
sr2.index = sr2.index.astype(str) # 行名を文字列型に変換
sr2["10":"20"]
10 Alice
20 Bob
Name: Name, dtype: object
実務で使う場合は、混乱を避けるためにインデックスがソートされた状態で使うことをおすすめします。
具体的に、ソートされていないSeriesを使って確認してみましょう。次のコードでは「行名"10"から行名"20"まで」を指定していますが、インデックスがソートされていないため、結果は空になっています。
sr3 = sr.copy()
sr3.index = ["20", "10", "30"] # ソートされていないインデックス
sr3["10":"20"]
Series([], Name: Name, dtype: object)
インデックスがソートされた状態だと、存在しない行名も指定できます。たとえば、次のコードでは「行名"10"から行名"3"まで」を指定しています。sr2のインデックスには"3"は存在しませんが、文字列の辞書順は"10", "20", "3", "30"なので、範囲に該当する最初の2行("10"と"20")が参照されます。
sr2["10":"3"]
10 Alice
20 Bob
Name: Name, dtype: object
なお、この省略形が使えるのは行名が文字列型の時だけです。もしdf[数値のスライス]と記述すると、df.iloc[行番号のスライス]とみなされるので注意しましょう。
※ Seriesも同様です。
行名のリスト(列名のリスト)による指定¶
行の指定に行名のリストを指定すると、指定した行を抜き出したDataFrameやSeriesになります。
df.loc[[10, 30]]
Name |
Point |
|
|---|---|---|
10 |
Alice |
87 |
30 |
Carol |
92 |
sr.loc[[10, 30]]
10 Alice
30 Carol
Name: Name, dtype: object
列名のリストも同様です。指定した列を抜き出したDataFrameになります。
df.loc[:, ["Name"]]
Name |
|
|---|---|
10 |
Alice |
20 |
Bob |
30 |
Carol |
列名のリストによる指定の省略形¶
df.loc[:, 列名のリスト]は、locを省略してdf[列名のリスト]と記述できます。
たとえば、下記の2行は同じ結果になります。
df.loc[:, ["Name"]]
df[["Name"]]
この書き方は、実務でDataFrameから分析に必要な列を抜き出す際によく使われます。
行の比較結果(列の比較結果)による指定¶
df.loc[行の比較結果]やsr.loc[行の比較結果]は、比較結果がTrueになる行を抜き出したDataFrameやSeriesになります。
行の比較結果の指定方法については、「行の絞り込み(ブールインデックス)」も参考にしてください。
たとえば、dfに対し「列Pointが80以上の行」を抜き出すと下記のようになります。
df.loc[df["Point"] >= 80]
Name |
Point |
|
|---|---|---|
10 |
Alice |
87 |
30 |
Carol |
92 |
また、srに対し「Aで始まる要素」を抜き出すと下記のようになります。
sr.loc[sr.str.startswith("A")]
10 Alice
Name: Name, dtype: object
行の比較結果による指定の省略形¶
df.loc[行の比較結果]は、locを省略してdf[行の比較結果]と記述できます。
たとえば、下記の2行は同じ結果になります。
※ Seriesも同様に使えます。
df.loc[df["Point"] >= 80]
df[df["Point"] >= 80]
簡潔に記述できるため、実務では省略形を使うことをおすすめします。
ただし、下記のように省略形に列名を指定して更新しようとすると警告が発生し、期待した結果になりません。
df5 = df.copy()
df5[df5["Point"] >= 80]["Point"] = 80
これは、d5f[df5["Point"] >= 80]がコピーを返し、更新が無視されるからです。
列名を指定して更新したい場合は、下記のようにlocを使って行と列を指定しましょう。
df5.loc[df5["Point"] >= 80, "Point"] = 80
df.loc[:, 列の比較結果]は、比較結果がTrueの列を抜き出したDataFrameになります。
たとえば、列名が"Na"で始まる列を抜き出すと下記のようになります。
df.loc[:, df.columns.str.startswith("Na")]
Name |
|
|---|---|
10 |
Alice |
20 |
Bob |
30 |
Carol |
NOTE
DataFrame.locやSeries.locについて、より詳しくはPyQの次のコンテンツで学べます。
パート「Seriesとインデックスと欠損値」
行番号によるデータ参照・更新(iloc)¶
DataFrame.ilocは、行番号や列番号を使ってデータの参照や更新ができます。Series.ilocは行番号でデータの参照や更新ができます。
コロンによる指定¶
loc同様、ilocでもコロン(:)は全行や全列を意味します。もし、列の指定を省略すると、:とみなされます。たとえば、df.iloc[行の指定]は、df.iloc[行の指定, :]と同じ結果になります。
行番号(列番号)による指定¶
df.iloc[行番号]は、指定した行(Series)になります。たとえば、先頭行を取得したい場合はdf.iloc[0]とします。
※ Seriesも同様に使えます。
df.iloc[0]
Name Alice
Point 87
Name: 10, dtype: object
df.iloc[:, 列番号]は、指定した列(Series)になります。
df.iloc[:, 0]
10 Alice
20 Bob
30 Carol
Name: Name, dtype: object
行番号のスライス(列番号のスライス)による指定¶
行番号のスライスを指定すると、指定した範囲の行を抜き出したDataFrameになります。リストのスライスと同じように使えます。
※ Seriesも同様に使えます。
df.iloc[:2]
Name |
Point |
|
|---|---|---|
10 |
Alice |
87 |
20 |
Bob |
65 |
列番号のスライスも同様です。指定した範囲の列を抜き出したDataFrameになります。
数値のスライスを用いたilocの省略形¶
df.iloc[行番号のスライス]をdf[数値のスライス]と記述できます。実務では、省略形の記述をおすすめします。
※ Seriesも同様に使えます。
df[:2]
Name |
Point |
|
|---|---|---|
10 |
Alice |
87 |
20 |
Bob |
65 |
行番号のリスト(列番号のリスト)による指定¶
行番号のリストを使って指定すると、指定した行を抜き出したDataFrameになります。
※ Seriesも同様に使えます。
df.iloc[[0, 1]]
Name |
Point |
|
|---|---|---|
10 |
Alice |
87 |
20 |
Bob |
65 |
列番号のリストも同様です。指定した列を抜き出したDataFrameになります。
df.iloc[:, [0]]
Name |
|
|---|---|
10 |
Alice |
20 |
Bob |
30 |
Carol |
NOTE
DataFrame.ilocとSeries.ilocについて、より詳しくはPyQの次のコンテンツで学べます。
パート「Seriesとインデックスと欠損値」
行の絞り込み(ブールインデックス)¶
DataFrameやSeriesの行の絞り込みには、ブールインデックスを使います。ブールインデックスとは、ブール値(True/False)を要素とするSeriesのことです。
ブールインデックスは、下記のように作成します。
Seriesとスカラーを比較した結果
SeriesとSeriesを比較した結果
要素がブール値のSeriesを返すメソッドの実行結果
なお、スカラーとは次元を持たないデータのことです。123などがスカラーであり、DataFrameやSeriesはスカラーではありません。
ここでは、上記のように作成したブールインデックスを比較結果と呼ぶことにします。 この比較結果は、下記のように行の絞り込みに使えます。
df[比較結果] # 比較結果がTrueの行を抜き出したもの
sr[比較結果] # 同上
下記のdfを使って、取得方法について順番に確認します。
df = pd.DataFrame(
[["Alice", 87, 76], ["Bob", 65, 88]],
columns=["Name", "Math", "Sci"],
)
df
Name |
Math |
Sci |
|
|---|---|---|---|
0 |
Alice |
87 |
76 |
1 |
Bob |
65 |
88 |
Seriesとスカラーの比較¶
まずは、Seriesとスカラーの比較について確認しましょう。この比較結果は、Series 比較演算子 値のように書きます。実行結果は、要素ごとの比較結果(ブール値)を格納したSeriesになります。
具体的な例で見てみましょう。下記のコードでは、「列Mathが80以上かどうか」の比較結果を取得しています。
df["Math"] >= 80
0 True
1 False
Name: Math, dtype: bool
結果を見ると、列Mathの先頭の値は87なので、結果の先頭はTrueになっていることがわかります。
この比較結果を使って df[比較結果] のように記述すると、結果がTrueの行だけを絞り込めます。
df[df["Math"] >= 80]
Name |
Math |
Sci |
|
|---|---|---|---|
0 |
Alice |
87 |
76 |
SeriesとSeriesの比較¶
続いて、SeriesとSeriesの比較について確認しましょう。この比較結果は、Series 比較演算子 Seriesのように書きます。
具体的な例で見てみましょう。下記のコードでは、「列Mathが列Sci未満かどうか」の比較結果を取得しています。
df["Math"] < df["Sci"]
0 False
1 True
dtype: bool
先頭の行は列Mathが87、列Scriが76なので、結果の先頭はFalseになります。
この比較結果を使って行を絞り込むと、下記のようになります。
df[df["Math"] < df["Sci"]]
Name |
Math |
Sci |
|
|---|---|---|---|
1 |
Bob |
65 |
88 |
要素がブール値のSeriesを返すメソッド¶
最後に、要素がブール値のSeriesを返すメソッドを使う例について確認しましょう。
列Mathが列Sci未満かどうかは、下記のようにメソッドlt()(less than)でも計算できます。結果は、ブール値のSeriesです。
df["Math"].lt(df["Sci"])
0 False
1 True
dtype: bool
この比較結果を使って行を絞り込むと、下記のようになります。
df[df["Math"].lt(df["Sci"])]
Name |
Math |
Sci |
|
|---|---|---|---|
1 |
Bob |
65 |
88 |
NOTE
ブールインデックスについて、より詳しくはPyQの次のコンテンツで学べます。
パート「データの絞り込み」
インデックスの設定(DataFrame.set_index())¶
インデックスの設定を行いたい場合はset_index()を使います。たとえば、特定の列をインデックスに移動したい場合、下記のようにします。
df.set_index(列名または列名のリスト)
具体例で確認しましょう。ある施設の日別、年齢別の料金を表すdfを使います。
df = pd.DataFrame(
[
["平日", "大人", 2000],
["平日", "小人", 1000],
["土日祝", "大人", 3000],
["土日祝", "小人", 1500],
],
columns=["日別", "年齢別", "料金"],
)
df
日別 |
年齢別 |
料金 |
|
|---|---|---|---|
0 |
平日 |
大人 |
2000 |
1 |
平日 |
小人 |
1000 |
2 |
土日祝 |
大人 |
3000 |
3 |
土日祝 |
小人 |
1500 |
1つの列をインデックスに設定(df.set_index(列名))¶
1つの列をインデックスに設定する場合は、set_index()に列名を指定します。
たとえば、列日別をインデックスとして設定するには以下のようにします。
df.set_index("日別")
|
年齢別 |
料金 |
|---|---|---|
平日 |
大人 |
2000 |
平日 |
小人 |
1000 |
土日祝 |
大人 |
3000 |
土日祝 |
小人 |
1500 |
複数列をインデックスに設定(df.set_index(列名のリスト))¶
複数の列をインデックスに設定する場合は、set_indexに列名のリストを指定します。
たとえば、列日別と列年齢別をインデックスに移動するには以下のようにします。
df.set_index(["日別", "年齢別"])
日別 | 年齢別 | 料金 |
|---|---|---|
| 平日 | 大人 | 2000 |
| 小人 | 1000 | |
| 土日祝 | 大人 | 3000 |
| 小人 | 1500 |
DataFrame.set_index()には、他にもさまざまな機能があります。詳しくは、下記を参照してください。
NOTE
DataFrame.set_index()について、より詳しくはPyQの次のコンテンツで学べます。
パート「Seriesとインデックスと欠損値」
インデックスのリセット(DataFrame.reset_index())¶
DataFrameのインデックスをリセットしたい場合、reset_index()が使えます。インデックスのリセットの仕方には、次のようなものがあります。
インデックスを通し番号に変換
インデックスを列に変換
それぞれ見ていきましょう。
インデックスを通し番号に変換(drop=True)¶
DataFrameのインデックスを通し番号にしたい場合、下記のようにします。
df.reset_index(drop=True)
具体的な例で見てみましょう。下記のコードでは、インデックスが不連続なdfを作成しています。
df = pd.DataFrame([2, np.nan, 1], columns=["Point"])
df = df.dropna() # 欠損値を除外してインデックスを不連続にする
df
Point |
|
|---|---|
0 |
2.0 |
2 |
1.0 |
インデックスを通し番号にするには、下記のようにreset_index(drop=True)を使います。
df.dropna().reset_index(drop=True)
Point |
|
|---|---|
0 |
2.0 |
1 |
1.0 |
結果を確認すると、不連続だったインデックス(0、2)が、連続したインデックス(0、1)に変換されていることがわかります。
インデックスを列に変換¶
DataFrameのインデックスを列に変換したい場合、下記のようにします。
df.reset_index()
具体例で確認しましょう。生徒の点数を表すdfを使います。
df = pd.DataFrame(
[
["Alice", "国語", 100],
["Alice", "数学", 80],
["Bob", "国語", 40],
["Bob", "理科", 80],
],
columns=["Name", "Subject", "Point"],
)
df
Name |
Subject |
Point |
|
|---|---|---|---|
0 |
Alice |
国語 |
100 |
1 |
Alice |
数学 |
80 |
2 |
Bob |
国語 |
40 |
3 |
Bob |
理科 |
80 |
下記のように、生徒ごとに点数の平均を取得したいとします。
Name |
Point |
|
|---|---|---|
0 |
Alice |
90.0 |
1 |
Bob |
60.0 |
生徒ごとの平均は、下記のようにgroupby()とmean()で計算できますが、生徒がインデックスになっています。
df.groupby("Name").mean()
|
Point |
|---|---|
Alice |
90.0 |
Bob |
60.0 |
インデックスを列に変換するには、下記のようにreset_index()を使います。
df.groupby("Name").mean().reset_index()
Name |
Point |
|
|---|---|---|
0 |
Alice |
90.0 |
1 |
Bob |
60.0 |
また、DataFrame.reset_index()には、他にもさまざまな機能があります。詳しくは、下記を参照してください。
NOTE
DataFrame.reset_index()について、より詳しくはPyQの次のコンテンツで学べます。
パート「Seriesとインデックスと欠損値」
Seriesのインデックスのリセット(Series.reset_index())¶
Seriesのインデックスをリセットしたい場合、DataFrame同様reset_index()を使います。主な使い方は、前節で紹介したDataFrameのreset_index()と同じです。
sr.reset_index(drop=True) # インデックスを通し番号に変換。結果はSeries
sr.reset_index() # 列をインデックスに変換。結果はDataFrame
具体例で確認しましょう。まずは生徒の点数を格納したdfを作成し、生徒ごとに点数の平均を計算します。今回は、この結果のSeriesであるsrを使います。
df = pd.DataFrame(
[
["Alice", "国語", 100],
["Alice", "数学", 80],
["Bob", "国語", 40],
["Bob", "理科", 80],
],
columns=["Name", "Subject", "Point"],
)
# 生徒ごとの点数の平均を計算
sr = df.groupby("Name").Point.mean()
sr
Name
Alice 90.0
Bob 60.0
Name: Point, dtype: float64
srのインデックスを通し番号にするには、下記のようにreset_index(drop=True)を使います。
sr.reset_index(drop=True)
0 90.0
1 60.0
Name: Point, dtype: float64
インデックスを列に移動したい場合は、下記のようにreset_index()を使います。
sr.reset_index()
Name |
Point |
|
|---|---|---|
0 |
Alice |
90.0 |
1 |
Bob |
60.0 |
Series.reset_index()には、他にもさまざまな機能があります。詳しくは、下記を参照してください。
データの結合(DataFrame.merge())¶
2つのDataFrameを結合したい場合、merge()が使えます。次のように結合方法とキーを指定可能です。
df1.merge(df2, how=結合方法, on=キー)
たとえば次のように実行すると、df1とdf2の共通する列をキーとし、そのキーの共通要素ごとに直積を作成して、それらを結合したDataFrameを作成します。なお、直積とは各要素の組み合わせをすべて網羅したものです(下図)。
df1.merge(df2, how="inner", on=None)
図:直積
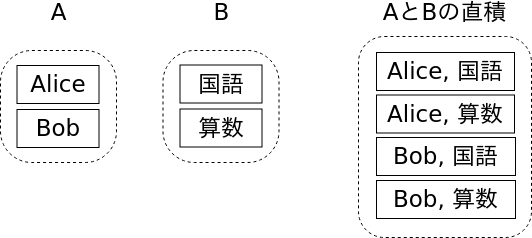
具体的な例で確認してみましょう。次のように、2つのDataFrameを用意して join()で結合します。
df1 = pd.DataFrame(
[[0, "Alice"], [0, "Bob"], [1, "Carol"]],
columns=["ID", "Name"],
)
df2 = pd.DataFrame(
[[0, "国語"], [0, "数学"]],
columns=["ID", "Subject"],
)
df1.merge(df2, how="inner", on=None)
ID |
Name |
Subject |
|
|---|---|---|---|
0 |
0 |
Alice |
国語 |
1 |
0 |
Alice |
数学 |
2 |
0 |
Bob |
国語 |
3 |
0 |
Bob |
数学 |
df1とdf2の共通する列はIDで、どちらも値が0の要素を含んでいます。
IDが0のデータは、df1ではAliceとBobの行、df2では国語と数学の行です。そのため、直積は上記のように「Aliceと国語」「Aliceと数学」「Bobと国語」「Bobと数学」の組み合わせになります。
また、df1には値が1の要素がありますが、df2にはありません。そのため、結合結果にはCarolのデータは含まれません。
結合方法の指定(引数how)¶
引数howには、キーのどの要素を対象とするかを指定します。デフォルトは"inner"です。
表:merge()の引数howで指定可能な結合方法
値 |
意味 |
|---|---|
|
|
|
|
|
両者のすべて |
|
両者の共通部分 |
|
キーを不使用 |
もし、df1に含まれるキーの要素をすべて含めたい場合は、how="left"を指定します。
df1.merge(df2, how="left")
ID |
Name |
Subject |
|
|---|---|---|---|
0 |
0 |
Alice |
国語 |
1 |
0 |
Alice |
数学 |
2 |
0 |
Bob |
国語 |
3 |
0 |
Bob |
数学 |
4 |
1 |
Carol |
NaN |
上記では、IDが1のデータ(Carol)も含まれます。しかし、IDが1のデータはdf2にはないので、列Subjectは欠損値になります。
キーの指定(引数on、left_on、right_on)¶
引数onには、キーとなる列名または列名のリストを指定します。デフォルトはNoneです。
onにNoneを指定すると、共通する列がキーとなります。
また、df1とdf2で異なる列名をキーとして対応させたい場合は、それぞれを引数left_on(df1用)と引数right_on(df2用)を指定します。
DataFrame.merge()には、他にもさまざまな機能があります。詳しくは、下記を参照してください。
NOTE
DataFrame.merge()について、より詳しくはPyQの次のコンテンツで学べます。
パート「pandasの表の加工」
データの結合(DataFrame.join())¶
2つのDataFrameを結合したい場合、join()が使えます。次のように結合方法とキーを指定可能です。
df1.join(df2, on=キー, how=結合方法)
使い方は前節で説明したmerge()と似ていますが、引数onでNoneを指定した時にmerge()では共通する列をキーとして使うのに対し、join()はインデックスをキーとして使います。また、引数howのデフォルト値は、merge()では"inner"(両者の共通部分)であるのに対し、join()は"left"(df1のすべて)です。
次のようにjoin()を実行すると、df1とdf2のインデックスをキーとし、df1のキーの要素ごとに直積を作成して、それらを結合したDataFrameを作成します。
df1.join(df2, on=None, how="left")
具体的な例で確認してみましょう。次のように、2つのDataFrameを用意して join()で結合します。
df1 = pd.DataFrame(
["Alice", "Bob", "Carol"],
index=[0, 0, 1],
columns=["Name"],
)
df2 = pd.DataFrame(
["国語", "数学"], index=[0, 0], columns=["Subject"]
)
df1.join(df2, on=None, how="left")
Name |
Subject |
|
|---|---|---|
0 |
Alice |
国語 |
0 |
Alice |
数学 |
0 |
Bob |
国語 |
0 |
Bob |
数学 |
1 |
Carol |
NaN |
df1のインデックスの要素は0と1です。
要素0のデータはdf1とdf2の両方にあり、df1ではAliceとBobの行、df2では国語と数学の行です。そのため、直積は上記の先頭4行のようになります。
要素1のデータはdf1にしかありません(Carolの行)。そのため直積は上記の最後の1行のようになり、Subjectは欠損値になります。
キーの指定(引数on)¶
引数onには、df1のキーとなる列名または列名のリストを指定します。デフォルトはNoneです。
onにNoneを指定すると、インデックスがキーとなります。
df3の列IDとdf2のインデックスをキーとする場合は、下記のようになります。
df3 = pd.DataFrame(
[[0, "Alice"], [0, "Bob"], [1, "Carol"]],
columns=["ID", "Name"],
)
df3.join(df2, on="ID", how="left")
ID |
Name |
Subject |
|
|---|---|---|---|
0 |
0 |
Alice |
国語 |
0 |
0 |
Alice |
数学 |
1 |
0 |
Bob |
国語 |
1 |
0 |
Bob |
数学 |
2 |
1 |
Carol |
NaN |
結合方法の指定(引数how)¶
引数howには、キーのどの要素を対象とするかを指定します。デフォルトは"left"です。
表:join()の引数howで指定可能な結合方法
値 |
意味 |
|---|---|
|
|
|
|
|
両者のすべて |
|
両者の共通部分 |
もし、両者の共通部分のキーの要素を対象にしたい場合は、how="inner"を指定します。
df1.join(df2, on=None, how="inner")
Name |
Subject |
|
|---|---|---|
0 |
Alice |
国語 |
0 |
Alice |
数学 |
0 |
Bob |
国語 |
0 |
Bob |
数学 |
上記では、インデックスが1のデータはdf1にしかないため、結合結果には含まれません。
DataFrame.join()には、他にもさまざまな機能があります。詳しくは、下記を参照してください。
関数の適用(DataFrame.apply() / Series.apply())¶
apply()は、指定した関数を列または行に一括で適用するメソッドです。DataFrameとSeriesの両方で使え、データを加工したい際に便利です。それぞれの使い方を下表にまとめました。
表:DataFrameとSeriesのapply()
種類 |
書き方の例 |
説明 |
|---|---|---|
Series |
|
指定した関数を、Seriesの各要素に一括で適用。 |
DataFrame |
|
指定した軸に沿って、行または列に関数を一括で適用。 |
具体的に、次のデータで考えてみましょう。
# 利用者の年齢と割引種別を格納したデータ
df = pd.DataFrame(
[[12, ""], [20, "学割利用"], [32, ""]], columns=["年齢", "割引種別"]
)
df
年齢 |
割引種別 |
|
|---|---|---|
0 |
12 |
|
1 |
20 |
学割利用 |
2 |
32 |
次のコードは、Seriesのapply() の例です。列年齢に対してcategorize()を適用し、年齢に応じて"大人"または"子供"と返しています。結果はSeriesになります。
def categorize(x):
# 引数xには、各要素の値が渡される
return "子供" if x < 13 else "大人"
# 列「年齢」の各要素にcategorize()を適用する
df["年齢"].apply(categorize)
0 子供
1 大人
2 大人
Name: age, dtype: object
次のコードは、DataFrameのapply()の例です。各行に対しcategorize()を適用し、年齢と割引種別の値から文字列を作成しています。結果はSeriesになります。
def categorize(sr):
# 引数srには、各行のSeriesが渡される
age_type = "子供" if sr["年齢"] < 13 else "大人"
coupon_type = f"({sr['割引種別']})" if sr["割引種別"] else ""
return age_type + coupon_type # 年齢と割引種別を連結
# 各行にcategorize()を適用する(列に沿った処理)
df.apply(categorize, axis=1)
0 子供
1 大人(学割利用)
2 大人
dtype: object
NOTE
apply()について、より詳しくはPyQの次のコンテンツで学べます。
クエスト「列や行に関数を適用しよう」
データのグループ化(DataFrame.groupby())¶
groupby()は、データをグループ化して処理するためのメソッドです。groupby()の結果(DataFrameGroupByオブジェクト)と集約・変換・抽出に関するメソッドを組み合わせることで、グループごとの処理を行えます(※)。ここでは主に集約について紹介します。
※ 変換のメソッドにはtransform()が、抽出のメソッドにはfilter()があります。
# 指定した列でグループ化(結果はDataFrameGroupByオブジェクト)
grouped = df.groupby(列名または列名のリスト)
# 集約メソッドと組み合わせて、グループごとにデータを集約
grouped.集約メソッド()
sum()、mean()、max()、 agg()など、DataFrameで使える集約メソッドは基本的にDataFrameGroupByでも使えます。具体的に、次のデータで考えてみましょう。
# 生徒ごとの身長と体重を記録したデータ
df = pd.DataFrame(
[["A", 172, 63], ["A", 160, 54], ["B", 155, 51], ["B", 162, 59]],
columns=["クラス", "身長", "体重"],
)
df
クラス |
身長 |
体重 |
|
|---|---|---|---|
0 |
A |
172 |
63 |
1 |
A |
160 |
54 |
2 |
B |
155 |
51 |
3 |
B |
162 |
59 |
次のコードでは、列クラスでグループ化して、グループごとの各列の平均値を計算しています。
# 各クラスの平均値
df.groupby("クラス").mean()
|
身長 |
体重 |
|---|---|---|
A |
166.0 |
58.5 |
B |
158.5 |
55.0 |
DataFrameGroupByオブジェクトで[]を使って列名を指定すると、特定の列のSeriesGroupByオブジェクトを取得できます。一部異なる点はありますが、SeriesGroupByではDataFrameGroupByと同じように集約メソッドなどが使えます。
# 各クラスの身長の平均値
df.groupby("クラス")["身長"].mean()
クラス
A 166.0
B 158.5
Name: 身長, dtype: float64
集約メソッドとしてagg()を使うと、より柔軟な集約が可能です。下表に基本的な使い方をまとめました。
表:agg()の指定方法と使用例
指定方法 |
説明 |
書き方の例 |
処理の例 |
|---|---|---|---|
文字列 |
文字列で指定した関数の処理で集約する( |
|
|
関数 |
指定した関数の処理で集約する |
|
|
リスト |
複数の集約値を一括で計算する |
|
|
辞書 |
列ごとに異なる方法を指定して集約する |
|
各列を次のように集約する |
NOTE
groupby()について、より詳しくはPyQの次のコンテンツで学べます。
パート「データのグループ化」


当コンテンツの知的財産権は株式会社ビープラウドに所属します。詳しくは利用規約をご確認ください。