正規表現¶
文字列から特定のパターンを探すのに、正規表現(reモジュール)を使います。
パターンで使う文字¶
パターンは、通常の文字や特殊文字などを組合せて表現します(日本語も使えます)。
| 特殊文字 | 説明 | 例 | matchする例 | matchしない例 |
|---|---|---|---|---|
| . | 改行以外の任意の一文字 | a.c | abc | ac abbc |
| ^ | 文字列の先頭 | ^ab | abc | zab |
| $ | 文字列の末尾 | ab$ | zab | abc |
| * | 直前の文字の0回以上の繰り返し | ab* | a ab abb | aa ac |
| + | 直前の文字の1回以上の繰り返し | ab+ | ab abb | a |
| ? | 直前の文字の0回または1回 | ab? | a ab | abb |
| {m} | 直前の文字のm回の繰り返し | a{2} | aa | a aaa |
| {m,n} | 直前の文字のm回からn回の繰り返し | a{1,2} | a aa | aaa |
| \ | 特殊文字のエスケープ | \. | . | a |
| [文字の集合] | 集合の中の1文字 | [a-c] | a b c | d |
| [^文字の集合] | 集合に含まれない1文字 | [^a-c] | d | a b c |
| | | いずれか | a|b | a b | c |
| () | グループ化 | (ab|cd) | ab cd | abc ac |
※ 「任意の一文字」とは、「何でも当てはめて良い一文字」を意味しています。
※ モードと呼ばれるもので、変わるものもありますが、詳細は省略します。
※ *や+では、なるべく長い文字列とマッチするように探索します。
※ *?や+?とすることで、なるべく短い文字列とマッチするように探索します。
※ 特殊文字そのものにマッチさせたい場合、r'\[]'のように、バックスラッシュを使います。
角括弧の補足¶
'[0-9]'は、'[0123456789]'と同じ意味になります。
小文字のアルファベットと数字を表したい場合は、'[a-z0-9]'となります。
'[a-z0-9_]'のように、ハイフン(-)を使う方法と使わない方法を混ぜても大丈夫です。
'[^文字集合]'は、文字集合以外になります。
特殊シーケンス¶
バックスラッシュで始まる特殊シーケンスもあります。
| 特殊シーケンス | 説明 | 同義のパターン |
|---|---|---|
| \d | 任意の数字 | ASCIIの場合、[0-9] |
| \D | \d以外 | |
| \s | 任意の空白文字 | ASCIIの場合、[ \t\n\r\f\v] |
| \S | \s以外 | |
| \w | 任意のUnicode単語文字 | ASCIIの場合、[a-xA-Z0-9_] |
| \W | \w以外 | |
| \A | 文字列の先頭 | ^ |
| \Z | 文字列の末尾 | $ |
※ 特殊シーケンスは、バックスラッシュとアルファベットの2文字です。 ※ ASCII以外のUnicodeでは、「同義のパターン」以外の文字もありえます。
特殊シーケンスの文字列表現は、r'\d'や'\\d'などがあります。
|で左右のどちらかのサブパターンにマッチさせられます。|はいくつでも使えます。
サブパターンの範囲を示すために括弧を使います。
match¶
re.match(パターン, 対象文字列)で対象文字列がパターンに先頭からマッチするかを調べます。
re.matchは、対象文字列の先頭からマッチする場合、matchオブジェクト(正規表現の結果をまとめたもの)を返します。マッチしない場合は、Noneを返します。
'.*$'は改行以外の任意の文字列にマッチしますので、'abc'にマッチします。
matchオブジェクトからマッチした文字列を取り出すには、group(0)を使います。
'.+$'は改行以外の任意の1文字以上の文字列にマッチしますので、''にマッチしません。
マッチしたかどうかは、if文でmatchオブジェクトを評価して判断できます。
re.match は、先頭から見ますので、パターンが $ で終わっていれば、全体にマッチするか調べることになります。
search¶
re.search(パターン, 対象文字列)でパターンに一致する部分を求めます。
パターン'"(.*)"'とすると、ダブルクォーテーションで囲まれた文字列を探します。
グループ¶
パターンに括弧が含まれていると、括弧内の文字列はグループとして取り出せます。
group(0):マッチした文字列全体group(1):1番目のグループ(最初の括弧内)group(2):2番目のグループ(2つ目の括弧内)
ORの補足¶
r'(ab|cde|\d+)$'というパターンでは、'ab'、'cde'、数字1文字以上のいずれかにマッチします。
ORを使いたいけど、グループは使いたくないというときがあります。
グループにしない括弧を使うことでできます。
'(...)'を'(?:...)'とするとグループになりません。
たとえば、r'(?:ab|cde|\d+)$'と書きます。
re.split¶
:または;で文字を区切ります。パターンが固定であれば、str.splitと同じになります。
対象文字列に区切り文字がなければ、対象文字列を要素とするリストが返ります。
re.sub¶
re.sub(パターン, 置換文字列, 対象文字列)では、置換文字列に以下が使えます。
r'\1':group(1)に対応r'\2':group(2)に対応
置換文字列をr'\2 \1'とすると、単語の交換みたいなことができます。
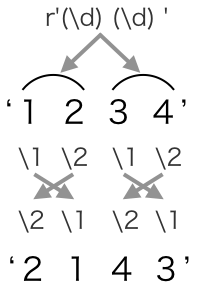
re.sub(r'(\d) (\d)', r'\2 \1', '1 2 3 4')の処理の流れ¶
最初に、
r'(\d) (\d)'は、'1 2 3 4'に対して、'1 2'にマッチし、\1 == '1'、\2 == '2'となります。変換指定が、
r'\2 \1'なので、変換後は'2 1'になります。次に、
r'(\d) (\d)'は、'1 2 3 4'に対して、'3 4'にマッチし、\1 == '3'、\2 == '4'となります。変換指定が、
r'\2 \1'なので、変換後は'4 3'になります。最終的に、
re.subは、2 1 4 3を返します。
re.findall¶
複数のパターンを取り出したいときは、re.findallが便利です。
公式ドキュメント¶
詳しくは 正規表現操作 を参照ください。


当コンテンツの知的財産権は株式会社ビープラウドに所属します。詳しくは利用規約をご確認ください。